Latest Blog Posts
Importing Postgres mailing list archives
Posted by Tomas Vondra on 2024-08-23 at 10:00
A couple weeks ago I needed to move my mailing list communication to a different mailbox. That sounds straightforward - go to the community account and resubscribe to all the lists with the new address, and then import a bit of history from the archives so that the client can show threads, search etc.
The first part worked like a charm, but importing the archives turned out to be a bit tricky, and I ran into a bunch of non-obvious issues. So here’s how I made that work in the end.
PGConf.dev 2024 - New logical replication features in PostgreSQL 17
Posted by Hayato Kuroda in Fujitsu on 2024-08-22 at 01:00

The PostgreSQL Development Conference 2024 was held earlier this year for the community to nurture the further expansion of PostgreSQL. Fujitsu's OSS team was delighted to give 2 talks in this year's exciting line-up that highlights topics on PostgreSQL development and community growth, featuring stories from users, developers, and community organizers.
Authentication monitoring in PostgreSQL
Posted by Rafia Sabih in EDB on 2024-08-20 at 13:21
PostgreSQL Internals Part 4: A Beginner’s Guide to Understanding WAL in PostgreSQL
Posted by semab tariq in Stormatics on 2024-08-20 at 12:22
In this blog, we'll dive into the concept of Write-Ahead Logging (WAL) in PostgreSQL, discussing its importance and examining the internal structure of WAL files.
The post PostgreSQL Internals Part 4: A Beginner’s Guide to Understanding WAL in PostgreSQL appeared first on Stormatics.
How to pick the first patch?
Posted by Tomas Vondra on 2024-08-20 at 10:00
Picking the topic for your first patch in any project is hard, and Postgres is no exception. Limited developer experience with important parts of the code make it difficult to judge feasibility/complexity of a feature idea. And if you’re not an experienced user, it may not be very obvious if a feature is beneficial. Let me share a couple simple suggestions on how to find a good topic for the first patch.
Postgres query re-optimisation in practice
Posted by Andrei Lepikhov in Postgres Professional on 2024-08-19 at 01:01
Today's story is about a re-optimisation feature I designed about a year ago for the Postgres Professional fork of PostgreSQL.
Curiously, after finishing the development and having tested the solution on different benchmarks, I found out that Michael Stonebraker et al. had already published some research in that area. Moreover, they used the same benchmark— Join Order Benchmark — to support their results. So, their authorship is obvious. As an excuse, I would say that my code looks closer to real-life usage, and during the implementation, I stuck and solved many problems that weren’t mentioned in the paper. So, in my opinion, this post still may be helpful.
It is clear that re-optimisation belongs to the class of 'enterprise' features, which means it is not wanted in the community code. So, the code is not published, but you can play with it and repeat the benchmark using the published docker container for the REL_16_STABLE Postgres branch.
Introduction
What was the impetus to begin this work? It was caused by many real cases that may be demonstrated clearly by the Join Order Benchmark. How much performance do you think Postgres loses if you change its preference of employing parallel workers from one to zero? Two times regression? What about 10 or 100 times slower?
The black line in the graph below shows the change in execution time of each query between two cases: with parallel workers disabled and with a single parallel worker per gather allowed. For details, see the test script and EXPLAINs, with and without parallel workers.
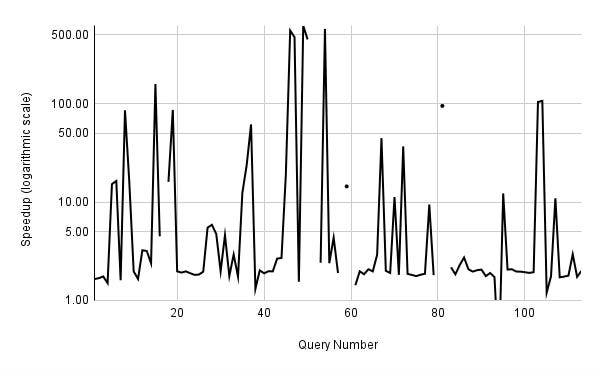
As you can see, the essential outcome is about a two-time speedup, which is logical when work is divided among two processes. But sometimes we see a 10-time speedup and even more, up to 500 times. Moreover, queries 14c, 22c, 22d, 25a, 25c, 31a, and 31c only finish their execution in a reasonable time with at least one parallel worker!
If you are hard-bitten enough to re
[...]PostgreSQL Hacking Workshop - September 2024
Posted by Robert Haas in EDB on 2024-08-19 at 01:00
Our talk for September 2024 will is by Andrey Borodin on his Youtube Channel "Byte Relay." The talk is Walk-through of Implementing Simple Postgres Patch: From sources to CI. I picked this talk for two reasons: first, in the poll I ran in the PostgreSQL Hacker Mentoring Discord, it got almost as many votes as the talk we did this month on the query planner. Second, I wanted to have at least some content that was targeted toward newer developers.
Read more »Good Benchmark Professionals and Postgres Benchmark Week
Posted by Jeremy Schneider in Amazon RDS on 2024-08-19 at 00:36
There are four major components to being a good benchmark professional:
- Methodology: A good benchmark professional defines the goals and non-goals of the exercise, makes strong choices on variables in the experiment, configures the SUT in a valid manner, and makes smart decisions about when and how to iterate the test.
- Investigation: A good benchmark professional asks “why” about the results of a test, taking initiative themself to dive deep into system behavior and questioning all unproven assumptions.
- Explainability: A good benchmark professional documents their findings with enough information for another professional to reproduce the test and the results, directly sharing scripts and configuration as far as possible, and clearly explains the results & the causes & the significance of the performance test.
- Accountability: A good benchmark professional publishes their performance test results and they thoughtfully and humbly engage with critics of the results in good faith, clarifying and updating and defending and iterating if needed, aiming to achieve as much consensus as possible.
Apparently it’s benchmark week in the Postgres world. I only have two data points but that’s enough for me!
First data point:
I’m visiting Portland. This Thursday Aug 22, the Portland Postgres Users Group (PDXPUG) is having a meetup where Paul Jungwirth is going to be talking about postgres benchmarking in general and walking though CMU’s Benchbase tool. I’ve spent a fair bit of time around Postgres performance testing myself, including Benchbase. I also have a few database friends around the Portland area. So at the last minute, I decided to drive down to Portland for the meetup this week and catch up with friends. It sounds like Mark Wong might be able to make it to the meetup (he’s also a very long time postgres benchmarking person) …and I’ve pinged some other folks with benchmarking and performance experience to see if we make it a real benchmark party.
It should be
[...]A TimescaleDB analytics trick
Posted by Kaarel Moppel on 2024-08-18 at 21:00
Contributions of w/c 2024-08-12 (week 33)
Posted by Jimmy Angelakos in postgres-contrib.org on 2024-08-18 at 13:37
- The PGDay Lowlands CfP team (Afsane Anand, Carole Arnaud, Chris Ellis, Gerard Zuidweg, Boriss Mejias - Chair) has published the conference schedule.
Postgres Powered by DuckDB: The Modern Data Stack in a Box
Posted by Marco Slot in Crunchy Data on 2024-08-16 at 16:00
Postgres for analytics has always been a huge question mark. By using PostgreSQL's extension APIs, integrating DuckDB as a query engine for state-of-the-art analytics performance without forking either project could Postgres be the analytics database too?
Bringing an analytical query engine into a transactional database system raises many interesting possibilities and questions. In this blog post I want to reflect on what makes these workloads and system architectures so different and what bringing them together means.
OLAP & OLTP: Never the twain shall meet
Database systems have always been divided into two worlds: Transactional and Analytical (traditionally referred to as OLTP) and OLAP (Online Transactional/Analytical Processing).
Both types of data stores use very similar concepts. The relational data model and SQL dominate. Writes, schema management, transactions and indexes use similar syntax and semantics. Many tools can interact with both types. Why then are they separate systems?
The answer has multiple facets. At a high level, OLTP involves doing a very large number of small queries and OLAP involves doing a small number of very large queries. They represent two extremes of the database workload spectrum. While many workloads fall somewhere in between, they can often be optimized or split until they can reasonably be handled by conventional OLTP or OLAP systems.
For many applications, the database system does the bulk of the critical computational work. Deep optimizations are essential for a database system to be useful and appealing, but optimization inherently comes with complexity. Consider that relational database systems have a vast amount of functionality and need to cater to a wide range of workloads. Building a versatile yet well-optimized database system can take a very long time.
Optimization is most effective when specializing for the characteristics of specific workloads, which practically always comes with the trade-off of being less optimized for other worklo
[...]CloudNativePG Recipe 11 - Isolating PostgreSQL Workloads in Kubernetes with Kind
Posted by Gabriele Bartolini in EDB on 2024-08-16 at 11:46
In modern Kubernetes environments, isolating PostgreSQL workloads is crucial for ensuring stability, security, and performance. This article, building on the previous CNPG Recipe #10, explores advanced techniques for isolating PostgreSQL instances using Kubernetes with Kind. By applying taints, labels, and anti-affinity rules, you can ensure that PostgreSQL nodes are dedicated exclusively to database workloads, preventing overlap with other services and enhancing fault tolerance. Whether you’re simulating a production environment or managing a live deployment, these strategies will help you maintain a robust and isolated PostgreSQL cluster in Kubernetes.
Authentication with SSL Client Certificates
Posted by Andrew Dunstan in EDB on 2024-08-15 at 16:23
Yet Another JSON parser for PostgreSQL
Posted by Andrew Dunstan in EDB on 2024-08-14 at 19:49
CloudNativePG Recipe 10 - Simulating Production PostgreSQL on Kubernetes with Kind
Posted by Gabriele Bartolini in EDB on 2024-08-14 at 10:37
This article provides a step-by-step guide to deploying PostgreSQL in Kubernetes using the kind tool (Kubernetes IN Docker) on a local machine, simulating a production-like environment. It explains how to create multi-node clusters and use node labels, specifically proposing the node-role.kubernetes.io/postgres label to designate PostgreSQL nodes. The article also demonstrates how to schedule PostgreSQL instances on these designated nodes, emphasizing the importance of workload isolation in Kubernetes environments. Thanks to Kubernetes’ portability, these recommendations apply to any cloud deployment—whether private, public, self-managed, or fully managed.
Remote Sinks in pgwatch3 by Akshat Jaimini
Posted by Pavlo Golub in Cybertec on 2024-08-13 at 11:10
As a mentor for Google Summer of Code (GSoC) 2024, I am thrilled to witness the innovative ideas and technical expertise that young minds bring to the table. This year, I have the pleasure of working with Akshat Jaimini on an exciting project that aims to enhance PostgreSQL monitoring through the development of RPC sinks for pgwatch3. Akshat's work focuses on extending pgwatch3 by developing a mechanism to allow Remote Procedure Call (RPC) sinks, which will offer more flexibility and integration possibilities for users.
At this point, I would like to hand over to Akshat, who will delve into the specifics of the project, its goals, and the challenges we aim to address. Akshat, the floor is yours!

Hello! I am Akshat Jaimini, a Computer Engineering Student from India. I was a part of PostgreSQL for the Google Summer of Code 2023 Program where I worked closely with the pgweb development team on developing a testing harness suite for the Official PostgreSQL website. Excited to be a part of the PostgreSQL community!
Sinks?
pgwatch v3 is well under works and with that comes the possibility of new and awesome features that were not there earlier. One such feature is the addition of ‘Remote Sinks’ in this awesome tool.
Sinks…?
Well if you have used pgwatch2 earlier, you would be familiar with the storage concept. Let me get you up to speed.
Previously we configured pgwatch in two ways: the Push and the Pull configs. First one will send store measurements somewhere directly, while the pull config allows scrapers to fetch measurements from pgwatch.
Regardless of the config being used, essentially all your metric measurements need to be stored somewhere. That particular ‘storage unit’ is referred to as a Sink in pgwatch v3.
So basically pgwatch fetches metric measurements from the ‘Source’ Database and sends/stores them in ‘Sinks’.
Why Remote Sinks?
Till now pgwatch supported PostgreSQL, JSON file and Prometheus as the possible sink solutions. Although these are great for th
[...]Will Postgres development rely on mailing lists forever?
Posted by Tomas Vondra on 2024-08-13 at 10:00
Postgres is pretty old. The open source project started in 1996, so close to 30 years ago. And since then, Postgres has become one of the most successful and popular databases. But it also means a lot of the development process reflects how things were done back then. The reliance on mailing lists is a good example of this heritage. Let’s talk about if / how this might change.
The new PostgreSQL 17 make dist
Posted by Peter Eisentraut in EDB on 2024-08-13 at 04:00
When the PostgreSQL project makes a release, the primary artifact of that is the publication of a source code tarball. That represents the output of all the work that went into the creation of the PostgreSQL software up to the point of the release. The source tarball is then used downstream by packagers to make binary packages (or file system images or installation scripts or similar things), or by some to build the software from source by hand.
Creating a source code tarball is actually quite tricky to do by hand. Of course, you could just run “tar” over a currently checked out source tree. But you need to be careful that the checkout is clean and not locally modified. You need to ensure that all the files that belong in the tarball end up there and no other files. There are certain source control files that you don’t want to include in the tarball. File permissions and file ownership need to be sane. And all this should work consistently across platforms and across time. Fortunately, this has all been scripted and has been pretty reliable over the years.
Additionally, a PostgreSQL source code tarball has included various prebuilt files. These are files that are not actually part of the source code checked into Git, but they would be built as part of a normal compilation. For example, a source code tarball has included prebuilt Bison and Flex files, various .c and .h files generated by Perl scripts, and HTML and man page documentation built from DocBook XML files. The reason for this is a mix of convenience and traditional practice. All these output files are platform-independent and independent of build options. So everyone will get the same ones anyway, so we might as well prebuild them. Also, that way, users of the source tarball won’t need the tools to build these files. For example, you didn’t actually need Perl to build PostgreSQL from a source tarball, because all the files generated from Perl scripts were already built. Also, historically (very historically), PostgreSQL was pushing the limits
[...]Stop Relying on IF NOT EXISTS for Concurrent Index Creation in PostgreSQL
Posted by Shayon Mukherjee on 2024-08-12 at 17:43
How to Build a PostgreSQL Patch Test Environment on Ubuntu 22.04
Posted by Alastair Turner in Percona on 2024-08-12 at 15:36
 While the well-established ways of building PostgreSQL from source still work, there are many new options on Linux as well. Postgres has adopted Meson as a build system, and there are more—and more granular—git commands. There’s even a new way to describe the sources for installing packages for my Ubuntu desktop, which is the default […]
While the well-established ways of building PostgreSQL from source still work, there are many new options on Linux as well. Postgres has adopted Meson as a build system, and there are more—and more granular—git commands. There’s even a new way to describe the sources for installing packages for my Ubuntu desktop, which is the default […]
file_fdw: Directly Query Flat Files in PostgreSQL Without Importing
Posted by semab tariq in Stormatics on 2024-08-12 at 11:19
The file_fdw (Foreign Data Wrapper) is a PostgreSQL extension that lets you access data stored in flat files, like CSV files, as if they were regular tables in your PostgreSQL database. This is useful for integrating external data sources without needing to import the data directly into your database.
The post file_fdw: Directly Query Flat Files in PostgreSQL Without Importing appeared first on Stormatics.
The urge of “T-shaped” profiles to smooth the challenges of running Postgres in Kubernetes
Posted by Gabriele Bartolini in EDB on 2024-08-12 at 10:12
As Kubernetes celebrates its tenth anniversary, the integration of PostgreSQL within this ecosystem is gaining momentum, offering challenges and opportunities, rather than threats, for database administrators (DBAs). This article explores the evolution of running PostgreSQL in Kubernetes, emphasising the importance of transitioning from traditional deployment methods to a cloud-native approach. It discusses the need for DBAs to expand their skills beyond the traditional scope, advocating for a “T-shaped” or even “comb-shaped” professional profile. By understanding key Kubernetes concepts and embracing the principles of “slowification”, simplification, and amplification, DBAs can effectively collaborate with developers and infrastructure teams. This approach enhances individual expertise and contributes to the broader adoption and optimisation of PostgreSQL in Kubernetes environments. The article highlights the critical role of community and shared knowledge in breaking down silos and fostering a collaborative culture, which is essential for the successful deployment and management of PostgreSQL in modern cloud-native infrastructures.
Probing indexes to survive data skew in Postgres
Posted by Andrei Lepikhov in Postgres Professional on 2024-08-12 at 00:01
This is the story of an unexpected challenge I encountered and a tiny but fearless response to address the Postgres optimiser underestimations caused by a data skew, miss in statistics or inconsistency between statistics and the data. The journey began with a user's complaint on query performance, which had quite unusual anamnesis.
The problem was with only one analytical query executed regularly by the schedule. For one of the involved tables, the query EXPLAIN had indicated a single tuple scan estimation, but the executor ended up fetching four million tuples from the disk. This unexpected turn of events led Postgres to choose parameterised NestLoop + Index Scans on each side of the join, causing the query to execute two orders of magnitude longer than with an optimal query plan. However, after executing the ANALYZE command, estimations became correct, and the query was executed fast enough.
Problem Analysis
The problematic table was a huge one and contained billions of rows. The user would load data in large batches over the weekends and immediately run the troubling query to identify new trends, comparing the fresh data with the existing data. One of the columns in the data was something like the current timestamp, which indicated the time of addition to the database, and it was unique for the whole batch. So, I immediately suspected that the user's data insertion pattern was the reason impacting query performance — something in statistics.
After discovery, I found that the source of errors was the estimation of trivial filters like 'x=N', where N had a massive number of duplicates in the table's column. Right after bulk insertion into the table, this filter was estimated by the stadistinct number. On the ANALYZE execution, this value was detected as a 'most common' value; its selectivity was saved in statistics, and at the subsequent query execution, this filter was estimated precisely by the MCV statistic.
Let's briefly dip into the logic of the equality filter selectivity to understa
[...]Contributions of w/c 2024-08-05 (week 32)
Posted by Jimmy Angelakos in postgres-contrib.org on 2024-08-11 at 14:05
- Andrew Atkinson’s book High Performance PostgreSQL for Rails has been published.
- Robert Haas ran the first PostgreSQL Hacking Workshop.
- Elizabeth Garrett Christensen is kicking off Postgres Meetup for All, a series of online meetups for PostgreSQL.
Exploring PostgreSQL 17: A Developer’s Guide to New Features – Part 4: Enhanced Merge Command.
Posted by Deepak Mahto on 2024-08-09 at 13:49
Welcome to Part 4 of our series exploring the exciting new features anticipated in the official PostgreSQL 17 release. In this series, we delve into newly features and discuss how they can benefit database developers and migration engineers transitioning to the latest version of PostgreSQL.
The first part of the blog covered the new features in PL/pgSQL – the procedural language in PostgreSQL 17.
The second part focused on the enhancements in null constraints and performance improvements in PostgreSQL 17.
The third part discussed how the COPY command has become more user-friendly in PostgreSQL 17.
Merge Statement in PostgreSQL 17
The MERGE statement allows us to write single DML statements with varying conditions to perform INSERT, UPDATE, or DELETE operations on a target table based on a data source. It offers multiple performance benefits and does not require an exclusion or unique constraint, unlike the INSERT ON CONFLICT statement.
Let’s explore an example involving the current_inventory table, where we want to update it based on transactions listed in the daily_updates table. We need to account for all statuses (sale, new, remove, restock) from daily_updates and perform the necessary operations on current_inventory.
Additionally, we’ll implement functionality to update the addinfo field in current_inventory to “no sale” if an item is not included in daily_updates.
CREATE TABLE current_inventory (
product_id BIGINT ,product_name VARCHAR(100),quantity INT,last_updated TIMESTAMP,addinfo text
);
CREATE TABLE daily_updates (
product_id BIGINT,product_name VARCHAR(100),quantity_change INT,update_type VARCHAR(10)
);
INSERT INTO current_inventory (product_id, product_name, quantity, last_updated)
VALUES (1, 'Laptop', 50, '2024-08-08 10:00:00'),(2, 'Smartphone', 100, '2024-08-08 10:00:00'),(3, 'Tablet', 30, '2024-08-08 10:00:00'),(4, 'Camera', 5, '2024-08-07 10:00:00'),(5, 'DVD Player', 5, '2024-08-07 10:00:00');
INSERT INTO daily_updates (product_id, product_name, quantity_cPostgres Troubleshooting - DiskFull ERROR could not resize shared memory segment
Posted by Jesse Soyland in Crunchy Data on 2024-08-09 at 12:00
There’s a couple super common Postgres errors you’re likely to encounter while using this database, especially with an application or ORM. One is the PG::DiskFull: ERROR: could not resize shared memory segment. It will look something like this.
"PG::DiskFull: ERROR: could not resize shared memory segment "/PostgreSQL.938232807" to 55334241 bytes: No space left on device"
Don’t panic
We see a good amount of support tickets from customers on this topic. If you see this error pass by in your logs. Don’t worry. Seriously. There’s no immediate reason to panic from a single one of these errors.
If you’re seeing them regularly or all the time, or your curious about how these are generated, let’s continue through some troubleshooting.
You aren’t really out of disk
In this case when it's stating "no space left on device" it's not talking about the entire disk, but rather the shared memory device at that exact moment. Segments are created there when a thread is allocating shared buffers for things like hashes, sorts, etc. Parallel workers will also allocate shared buffers. When there are not sufficient shared buffers remaining, the statement terminates with that sort of error.
The ‘disk full’ part of this error message is a bit of a red herring. This is an error that you'll see when your Postgres instance fails to allocate more memory in support of a query. It is not a real disk full message. Sometimes this happens when modest memory consuming queries that execute very slowly will end up tipping you past the available memory. Other times a huge memory-intensive query comes and takes a huge chunk of memory to cause this issue.
Why don’t these spill out to temp, like normally large queries? Well you probably just went over the total memory allocation. Work_mem is allocated for each query node that needs it, rather than once per query or session, meaning that a session can potentially consume many multiples of work_mem. For example, if max_parallel_workers is 8 and work_mem is 384MB, it's possi
[...]PG Phriday: My Postgres is Rusty
Posted by Shaun M. Thomas in Tembo on 2024-08-09 at 12:00
Postgres and Rust go together like peanut butter and chocolate, or ice-cream and root beer, or Batman and Robin, or mice and cheese, or sand on a beach, or crabs and elephants! Err, maybe scratch that last one.
Hmmmmm…
Well regardless, there’s a whole lot of Rust going on in the Postgres world these days, especially thanks to contributions from the PGRX project. As a relative novice to Rust, I figured it was time to see what all the fuss was about and tentatively dip a foot into those turbulent and unforgiving waters.
Postgres Troubleshooting - DiskFull ERROR could not resize shared memory segment
Posted by Jesse Soyland in Crunchy Data on 2024-08-09 at 12:00
There’s a couple super common Postgres errors you’re likely to encounter while using this database, especially with an application or ORM. One is the PG::DiskFull: ERROR: could not resize shared memory segment. It will look something like this.
"PG::DiskFull: ERROR: could not resize shared memory segment "/PostgreSQL.938232807" to 55334241 bytes: No space left on device"
Don’t panic
We see a good amount of support tickets from customers on this topic. If you see this error pass by in your logs. Don’t worry. Seriously. There’s no immediate reason to panic from a single one of these errors.
If you’re seeing them regularly or all the time, or your curious about how these are generated, let’s continue through some troubleshooting.
You aren’t really out of disk
In this case when it's stating "no space left on device" it's not talking about the entire disk, but rather the shared memory device at that exact moment. Segments are created there when a thread is allocating shared buffers for things like hashes, sorts, etc. Parallel workers will also allocate shared buffers. When there are not sufficient shared buffers remaining, the statement terminates with that sort of error.
The ‘disk full’ part of this error message is a bit of a red herring. This is an error that you'll see when your Postgres instance fails to allocate more memory in support of a query. It is not a real disk full message. Sometimes this happens when modest memory consuming queries that execute very slowly will end up tipping you past the available memory. Other times a huge memory-intensive query comes and takes a huge chunk of memory to cause this issue.
Why don’t these spill out to temp, like normally large queries? Well you probably just went over the total memory allocation. Work_mem is allocated for each query node that needs it, rather than once per query or session, meaning that a session can potentially consume many multiples of work_mem. For example, if max_parallel_workers is 8 and work_mem is 384MB, it's possi
[...]Postgres Troubleshooting - DiskFull ERROR could not resize shared memory segment
Posted by Jesse Soyland in Crunchy Data on 2024-08-09 at 12:00
There’s a couple super common Postgres errors you’re likely to encounter while using this database, especially with an application or ORM. One is the PG::DiskFull: ERROR: could not resize shared memory segment. It will look something like this.
"PG::DiskFull: ERROR: could not resize shared memory segment "/PostgreSQL.938232807" to 55334241 bytes: No space left on device"
Don’t panic
We see a good amount of support tickets from customers on this topic. If you see this error pass by in your logs. Don’t worry. Seriously. There’s no immediate reason to panic from a single one of these errors.
If you’re seeing them regularly or all the time, or your curious about how these are generated, let’s continue through some troubleshooting.
You aren’t really out of disk
In this case when it's stating "no space left on device" it's not talking about the entire disk, but rather the shared memory device at that exact moment. Segments are created there when a thread is allocating shared buffers for things like hashes, sorts, etc. Parallel workers will also allocate shared buffers. When there are not sufficient shared buffers remaining, the statement terminates with that sort of error.
The ‘disk full’ part of this error message is a bit of a red herring. This is an error that you'll see when your Postgres instance fails to allocate more memory in support of a query. It is not a real disk full message. Sometimes this happens when modest memory consuming queries that execute very slowly will end up tipping you past the available memory. Other times a huge memory-intensive query comes and takes a huge chunk of memory to cause this issue.
Why don’t these spill out to temp, like normally large queries? Well you probably just went over the total memory allocation. Work_mem is allocated for each query node that needs it, rather than once per query or session, meaning that a session can potentially consume many multiples of work_mem. For example, if max_parallel_workers is 8 and work_mem is 384MB, it's possi
[...]Why you should upgrade PostgreSQL today
Posted by Gülçin Yıldırım Jelínek in Xata on 2024-08-09 at 00:00
Top posters
Number of posts in the past two months
 Andrei Lepikhov (Postgres Professional) - 9
Andrei Lepikhov (Postgres Professional) - 9- Jimmy Angelakos (postgres-contrib.org) - 8
- Gabriele Bartolini (EDB) - 7
- David Wheeler (Tembo) - 5
- semab tariq (Stormatics) - 5
- Karen Jex (Crunchy Data) - 4
- Deepak Mahto - 4
- Andreas 'ads' Scherbaum - 4
- Tomas Vondra - 4
- Andrew Atkinson - 4
Top teams
Number of posts in the past two months
- EDB - 16
- Crunchy Data - 11
- Postgres Professional - 9
- Stormatics - 9
- Cybertec - 8
- postgres-contrib.org - 8
- Tembo - 7
- Xata - 6
- Percona - 5
- PostGIS - 2
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.