Latest Blog Posts
Operating PostgreSQL as a Data Source for Analytics Pipelines – Recap from the Stuttgart Meetup
Posted by Ilya Kosmodemiansky in Data Egret on 2025-07-01 at 11:29
PostgreSQL user groups are a fantastic way to build new connections and engage with the local community. Last week, I had the pleasure of speaking at the Stuttgart meetup, where I gave a talk on “Operating PostgreSQL as a Data Source for Analytics Pipelines.”
Below are my slides and a brief overview of the talk. If you missed the meetup but would be interested in an online repeat, let me know in the comments below!
PostgreSQL in Evolving Analytics Pipelines
As modern analytics pipelines evolve beyond simple dashboards into real-time and ML-driven environments, PostgreSQL continues to prove itself as a powerful, flexible, and community-driven database.
In my talk, I explored how PostgreSQL fits into modern data workflows and how to operate it effectively as a source for analytics.
From OLTP to Analytics
PostgreSQL is widely used for OLTP workloads – but can it serve OLAP needs as well? With physical or logical replication, PostgreSQL can act as a robust data source for analytics, enabling teams to offload read-intensive queries without compromising production.
Physical replication provides an easy-to-operate, read-only copy of your production PostgreSQL database. It lets you use the full power of SQL and relational features for reporting – without the risk of data scientists or analysts impacting production. It offers strong performance, though with some limitations: no materialized views, no temporary tables, and limited schema flexibility. Honestly, there are more ways analysts could harm production even from the replica side.
Logical replication offers a better solution:
- It allows schema adaptation (e.g., different partitioning strategies)
- Data retention beyond what’s on the primary
- Support for multiple data sources feeding into one destination
However, it also brings complexity – especially around DDL handling, failover, and more awareness from participating teams.
The Shift Toward Modern Data Analytics
Data analytics in 2025 is more than jus
[...]Behind the scenes: Speeding up pgstream snapshots for PostgreSQL
Posted by Esther Minano in Xata on 2025-07-01 at 10:30
From 99.9% to 99.99%: Building PostgreSQL Resilience into Your Product Architecture
Posted by Umair Shahid in Stormatics on 2025-07-01 at 09:55
The PG_TDE Extension Is Now Ready for Production
Posted by Jan Wieremjewicz in Percona on 2025-06-30 at 16:00
 Lately, it feels like every time I go to a technical conference, someone is talking about how great PostgreSQL is. I’d think it’s just me noticing, but the rankings and surveys say otherwise. PostgreSQL is simply very popular. From old-school bare metal setups to VMs, containers, and fully managed cloud databases, PostgreSQL keeps gaining ground. And […]
Lately, it feels like every time I go to a technical conference, someone is talking about how great PostgreSQL is. I’d think it’s just me noticing, but the rankings and surveys say otherwise. PostgreSQL is simply very popular. From old-school bare metal setups to VMs, containers, and fully managed cloud databases, PostgreSQL keeps gaining ground. And […]
Samed YILDIRIM
Posted by Andreas 'ads' Scherbaum on 2025-06-30 at 14:00
PgPedia Week, 2025-06-29
Posted by Ian Barwick on 2025-06-30 at 10:50
Housekeeping announcements:
this website's PostgreSQL installation is now on version 17 ( insert champagne emoji here ) the search function now works properly with non-ASCII characters ( there was an embarrassing oversight which went unnoticed until someone kindly pointed it out ) PostgreSQL 18 changes this weekThis week there have been a couple of renamings:
psql 's meta-command \close was renamed \close_prepared pg_createsubscriber 's option --remove was renamed to --cleanBoth of these items were added during the PostgreSQL 18 development cycle so do not have any implications for backwards compatibility.
There have also been some fixes related to:
comments on NOT NULL constraints virtual/generated columnsSee below for other commits of note.
How often is the query plan optimal?
Posted by Tomas Vondra on 2025-06-30 at 10:00
The basic promise of a query optimizer is that it picks the “optimal” query plan. But there’s a catch - the plan selection relies on cost estimates, calculated from selectivity estimates and cost of basic resources (I/O, CPU, …). So the question is, how often do we actually pick the “fastest” plan? And the truth is we actually make mistakes quite often.
Consider the following chart, with durations of a simple SELECT query with a range condition. The condition is varied to match different fractions of the table, shown on the x-axis (fraction of pages with matching rows). The plan is forced to use different scan methods using enable_ options, and the dark points mark runs when the scan method “won” even without using the enable_ parameters.

It shows that for selectivities ~1-5% (the x-axis is logarithmic), the planner picks an index scan, but this happens to be a poor choice. It takes up to ~10 seconds, and a simple “dumb” sequential scan would complete the query in ~2 seconds.
Performance Test for Percona Transparent Data Encryption (TDE)
Posted by Andreas Scherbaum on 2025-06-29 at 22:00
PgPedia Week, 2025-06-22
Posted by Ian Barwick on 2025-06-28 at 04:22
PgPedia Week has been delayed this week due to malaise and other personal circumstances.
PostgreSQL 18 changes this week pg_dump has gained the ability to dump statistics on foreign tables various bugfixes for the new amcheck function gin_index_check() PostgreSQL 18 articles PostgreSQL 18 just dropped: 10 powerful new features devs need to know (2025-06-20) - Devlink Tips Preserve optimizer statistics during major upgrades with PostgreSQL v18 (2025-06-17) - Laurenz Albe / CYBERTECChoosing the Right Barman Backup Type and Mode for Your PostgreSQL Highly Available Cluster
Posted by semab tariq in Stormatics on 2025-06-27 at 10:55
When running a PostgreSQL database in a High Availability (HA) cluster, it’s easy to assume that having multiple nodes means your data is safe. But HA is not a replacement for backups. If someone accidentally deletes important data or runs a wrong update query, that change will quickly spread to all nodes in the cluster. Without proper safeguards, that data is gone everywhere. In these cases, only a backup can help you restore what was lost.
The case mentioned above isn’t the only reason backups are important. In fact, many industries have strict compliance requirements that make regular backups mandatory. This makes backups essential not just for recovering lost data, but also for meeting regulatory standards.
Barman is a popular tool in the PostgreSQL ecosystem for managing backups, especially in High Availability (HA) environments. It’s known for being easy to set up and for offering multiple types and modes of backups. However, this flexibility can also be a bit overwhelming at first. That’s why I’m writing this blog to break down each backup option in a simple and clear way, so you can choose the one that best fits your business needs.
1. Backup Type in Barman
Barman primarily supports three backup types through various combinations of backup methods. The table below highlights the/z key differences between them
| Feature | Full Backup | Incremental Backup | Differential backup |
| Data Captured | An entire database at a specific point in time. | Changes since the last backup (full or incremental). | Changes since the last full backup. |
| Relative To | N/A (it’s the foundation) | Previous backup (full or incremental). | The last full backup. |
Entity Relationship Maps
Posted by Dave Stokes on 2025-06-25 at 13:26
Even the most experienced database professionals are known to feel a little anxious when peering into an unfamiliar database. Hopefully, they inspect to see how the data is normalized and how the various tables are combined to answer complex queries. Entity Relationship Maps (ERM) provide a visual overview of how tables are related and can document the structure of the data.
The Community Edition of DBeaver can provide an ERM easily. First, connect to the database. Right-click on the 'Tables' and then select 'View Diagram'.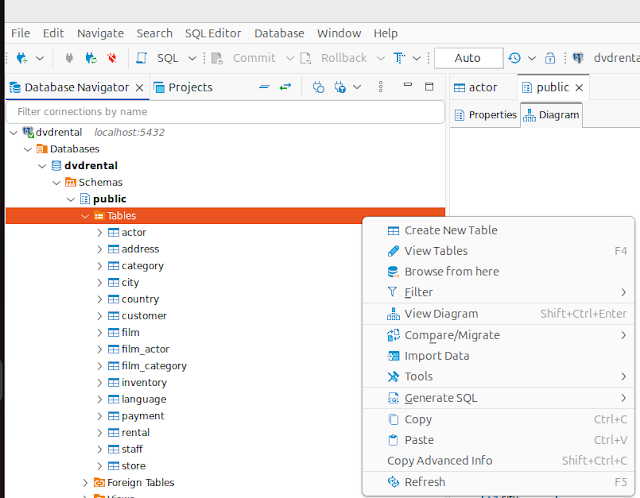
The ERM is then displayed.

And it gets better! If you are not sure how two tables are joined? Click on the link between the tables, and the names of the columns you will want to use in your JOIN statement are highlighted.
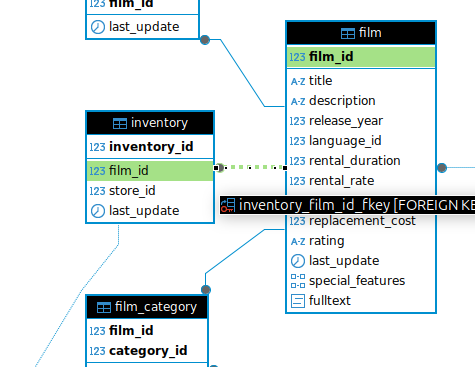
Conclusion
Exploring an unfamiliar database can be daunting. But Entity Relationship Maps provide a way to navigate the territory. And Dbeaver is a fantastic tool for working with databases.
CNPG Recipe 20 – Finer Control of Postgres Clusters with Readiness Probes
Posted by Gabriele Bartolini in EDB on 2025-06-25 at 06:04
Explore the new readiness probe introduced in CloudNativePG 1.26, which advances Kubernetes-native lifecycle management for PostgreSQL. Building on the improved probing infrastructure discussed in my previous article, this piece focuses on how readiness probes ensure that only fully synchronised and healthy instances—particularly replicas—are eligible to serve traffic or be promoted to primary. Special emphasis is placed on the streaming probe type and its integration with synchronous replication, giving administrators fine-grained control over failover behaviour and data consistency.
PGConf.EU 2025 - Registration opened
Posted by Magnus Hagander in PostgreSQL Europe on 2025-06-24 at 14:37
The registration for PGConf.EU 2025, which will take place on 21-24 October in Riga, is now open.
We have a limited number of tickets available for purchase with the discount code EARLYBIRD.
This year, the first day of training sessions has been replaced with a Community Events Day. This day has a more limited space, and can be booked as part of the conference registration process or added later, as long as seats last.
We hope you will be able to join us in Riga in October!
Beyond the Basics of Logical Replication
Posted by Radim Marek on 2025-06-24 at 07:10
With First Steps with Logical Replication we set up a basic working replication between a publisher and a subscriber and were introduced to the fundamental concepts. In this article, we're going to expand on the practical aspects of logical replication operational management, monitoring, and dive deep into the foundations of logical decoding.
Initial Data Copy#
As we demonstrated in the first part, when setting up the subscriber, you can choose (or not to) to rely on initial data copy using the option WITH (copy_data = false). While the default copy is incredibly useful behavior, this default has characteristics you should understand before using it in a production environment.
The mechanism effectively asks the publisher to copy the table data by taking a snapshot (courtesy of MVCC), sending it to the subscriber, and thanks to the replication slot "bookmark," seamlessly continues streaming the changes from the point the snapshot was taken.
Simplicity is the key feature here, as a single command handles the snapshot, transfer, and transition to ongoing streaming.
The trade-off you're making is when it comes to performance, solely due to the fact that it's using a single process per table. While it works almost instantly for test tables, you will encounter notable delay and overhead when dealing with tables with gigabytes of data.
Although parallelism can be controlled by the max_sync_workers_per_subscription configuration parameter, it still might leave you waiting for hours (and days) for any real-life database to get replicated. You can monitor whether the tables have already been synchronized or are still waiting/in progress using the pg_subscription_rel catalog.
SELECT srrelid::regclass AS table_name, srsubstate
FROM pg_subscription_rel;
Where each table will have one of the following states:
-
inot yet started -
dcopy is in progress -
ssyncing (or waiting for confirmation) -
rdone & replicating
Luckily, the state r indicates that the s
Contributions for the week of 2025-06-09 (Week 24)
Posted by Cornelia Biacsics in postgres-contrib.org on 2025-06-24 at 06:36
On June, 9th, Andrzej Nowicki held a talk about “From Queries to Pints: Building a Beer Recommendation System with pgvector” at the Malmö PostgreSQL User Group.
On June, 3rd the 5. PostgreSQL User Group NRW MeetUp took place in Germany.
Speakers:
* Josef Machytka about “Boldly Migrate to PostgreSQL - Introducing credativ-pg-migrator" * Mathis Rudolf about "PostgreSQL Locking – Das I in ACID" * Christoph Berg about "Modern VACUUM"
POSETTE: An Event for Postgres 2025 took place June 10-12 online. Organized by:
- Aaron Wislang
- Abe Omorogbe
- Ama Kusi
- Bilge Erdim
- Jeremy Asomaning
- Linda Leste
- Pooja Yarabothu
- Teresa Giacomini
Talk Selection Team: * Claire Giordano * Daniel Gustafsson * Krishnakumar “KK” Ravi * Melanie Plageman
Hosts: * Adam Wolk * Boriss Mejías * Claire Giordano * Derk van Veen * Floor Drees * Melanie Plageman * Thomas Munro
Speakers: * Abe Omorogbe * Adam Wolk * Alexander Kukushkin * Amit Langote * Ashutosh Bapat * Bohan Zhang * Boriss Mejías * Bruce Momjian * Charles Feddersen * Chris Ellis * Cédric Villemain * David Rowley * Derk van Veen * Ellyne Phneah * Gayathri Paderla * Heikki Linnakangas * Jan Karremans * Jelte Fennema-Nio * Jimmy Zelinskie * Johannes Schuetzner * Karen Jex * Krishnakumar “KK” Ravi * Lukas Fittl * Marco Slot * Matt McFarland * Michael John Pena * Nacho Alonso Portillo * Neeta Goel * Nitin Jadhav * Palak Chaturvedi * Pamela Fox * Peter Farkas * Philippe Noël * Polina Bungina * Rahila Syed * Robert Haas * Sandeep Rajeev * Sarah Conway * Sarat Balijapelli * Shinya Kato * Silvano Coriani * Taiob Ali * Tomas Vondra * Varun Dhawan * Vinod Sridharan
Waiting for SQL:202y: Vectors
Posted by Peter Eisentraut in EDB on 2025-06-24 at 04:00
It’s been a while since SQL:2023 was published, and work on the SQL standard continues. Nowadays, everyone in the database field wants vectors, and SQL now has them, too.
(I’m using the term “SQL:202y” for “the next SQL standard after SQL:2023”. I took this naming convention from the C standard, but it’s not an official term for the SQL standard. The current schedule suggests a new release in 2028, but we’ll see.)
Vectors are a popular topic for databases now, related to LLM and “AI” use cases. There is lots of information about this out there; I’m going to keep it simple here and just aim to describe the new SQL features. The basic idea is that you have some relational data in tables, let’s say textual product descriptions, or perhaps images. And then you run this data through … something?, an LLM? — this part is not covered by SQL at the moment — and you get a back vectors. And the idea is that vectors that are mathematically close to each other represent semantically similar data. So where before an application might have searched for “matching” things by just string equality or pattern matching or full-text search, it could now match semantically. Many database management systems have added support for this now, so it makes sense to standardize some of the common parts.
So there is now a new data type in SQL called vector:
CREATE TABLE items (
id int PRIMARY KEY,
somedata varchar,
embedding vector(100, integer)
);
The vector type takes two arguments: A dimension count and a coordinate type. The coordinate type is either an existing numeric type or possibly one of additional implementation-defined keywords. For example, an implementation might choose to support vectors with float16 internal values.
Here is how you could insert data into this type:
INSERT INTO items VALUES (1, 'foo', vector('[1,2,3,4,5,...]', 100, integer));
The vector() constructor takes a serialization of the actual vector data and again a dimension count and a coordinate type.
Again, how you actuall
[...]Suraj Kharage
Posted by Andreas 'ads' Scherbaum on 2025-06-23 at 14:00
PGDay UK 2025 - Registration open
Posted by Dave Page in PGDay UK on 2025-06-23 at 13:45
PGDay UK 2025 will be held in London, England, on Tuesday, September 9, 2025 at the Cavendish Conference Centre.
It features a full day with a track of PostgreSQL presentations from global PostgreSQL experts. It will cover a wide range of topics of interest.
Registration has now opened. Seats are limited so we recommend that you register early if you are interested! There are 20 Early bird discounted tickets available until the 31th of July 2025; grab yours before they run out or the campaign ends.
We will publish the schedule soon.
PGDay.UK is proud to be a PostgreSQL Community Recognised Conference.
We look forward to seeing you in London!
pgstream v0.7.1: JSON transformers, progress tracking and wildcard support for snapshots
Posted by Ahmet Gedemenli in Xata on 2025-06-20 at 11:45
Which PostgreSQL HA Solution Fits Your Needs: Pgpool or Patroni?
Posted by semab tariq in Stormatics on 2025-06-20 at 11:13
When designing a highly available PostgreSQL cluster, two popular tools often come into the conversation: Pgpool-II and Patroni. Both are widely used in production environments, offer solid performance, and aim to improve resilience and reduce downtime; however, they take different approaches to achieving this goal.
We often get questions during webinars/talks and customer calls about which tool is better suited for production deployments. So, we decided to put together this blog to help you understand the differences and guide you in choosing the right solution based on your specific use case.
Before we dive into comparing these two great tools for achieving high availability, let’s first take a quick look at some of the key components involved in building a highly available and resilient setup.
Load Balancing
Load balancing helps distribute incoming SELECT queries evenly across read replicas. By offloading read traffic from the primary node, it can focus on handling write operations more efficiently. Heavy read workloads like reporting queries or dashboards can be directed to standby nodes, reducing the burden on the primary. This can also increase the overall transactions per second (TPS)
Connection Pooling
Connection pooling helps manage database connections efficiently, especially in high-concurrency environments. PostgreSQL has a connection limit per server, and opening/closing connections is expensive. Connection poolers can maintain a pool of persistent connections and reuse them for incoming client requests, which reduces overhead and boosts performance. This is equally important when many clients or applications interact with the database simultaneously.
Auto Failover
Auto failover ensures that when the primary database goes down, another healthy standby is automatically promoted to take its place, minimizing manual intervention. Auto failover is a central component to achieving true high availability and reducing downtime during node failures.
Consensus-Based Voti
[...]The differences between OrioleDB and Neon
Posted by Alexander Korotkov on 2025-06-20 at 00:00
In a recent Hacker News discussion, there was some confusion about the differences between OrioleDB and Neon. Both look alike at first glance. Both promise a "next‑gen Postgres". Both have support for cloud‑native storage.
This post explains how the two projects differ in practice. And importantly, OrioleDB is more than an undo log for PostgreSQL.
The Core Differences
OrioleDB
OrioleDB is a Postgres extension. It implements a Table Access Method to replace the default storage method (Heap), providing the following key features:
- MVCC based on UNDO, which prevents bloat as much as possible;
- IO-friendly copy‑on‑write checkpoints with very compact row‑level WAL;
- An effective shared memory caching layer based on squizzled pointers.
Neon
Neon uses the default Table Access Method (Heap) and replaces the storage layer. The WAL is written to the safekeepers, and blocks are read from page servers backed by object storage, providing instant branching and scale-to-zero capabilities.
Architecture comparison
CPU Scalability
OrioleDB eliminates scalability bottlenecks in the PostgreSQL buffer manager and WAL writer by introducing a new shared memory caching layer based on squizzled pointers and row-level write-ahead logging (WAL). Therefore, OrioleDB can handle a high-intensity read-write workload on large virtual machines.
Neon compute nodes have roughly the same scalability as stock PostgreSQL. Still, Neon allows for the instant addition of more read-only compute nodes connected to the same multi-tenant storage.
IO Scalability
OrioleDB implements copy-on-write checkpoints, which improve locality of writes. Also, OrioleDB’s row-level WAL saves write IOPS due to its smaller volume.
Neon implements a distributed network storage layer that can potentially scale to infinity. The drawback is network latency, which could be very significant in contrast with fast local NVMe.
VACUUM & Data bloat
OrioleDB implements block-level and row-level UNDO log
[...]PostgreSQL Hacking + Patch Review Workshops for July 2025
Posted by Robert Haas in EDB on 2025-06-19 at 18:01
PostgreSQL active-active replication, do you really need it?
Posted by Jan Wieremjewicz in Percona on 2025-06-18 at 00:00
PostgreSQL active-active replication, do you really need it?
Before we start, what is active-active?
Active-active, also referred to as multi-primary, is a setup where multiple database nodes can accept writes at the same time and propagate those changes to the others. In comparison, regular streaming replication in PostgreSQL allows only one node (the primary) to accept writes. All other nodes (replicas) are read-only and follow changes.
In an active-active setup:
CNPG Recipe 19 – Finer Control Over Postgres Startup with Probes
Posted by Gabriele Bartolini in EDB on 2025-06-17 at 10:17
CloudNativePG 1.26 introduces enhanced support for Kubernetes startup probes, giving users finer control over how and when PostgreSQL instances are marked as “started.” This article explores the new capabilities, including both basic and advanced configuration modes, and explains the different probe strategies—such as pg_isready, SQL query, and streaming for replicas. It provides practical guidance for improving the reliability of high-availability Postgres clusters by aligning startup conditions with actual database readiness.
Preserve optimizer statistics during major upgrades with PostgreSQL v18
Posted by Laurenz Albe in Cybertec on 2025-06-17 at 09:07

© Laurenz Albe 2025
Everybody wants good performance. When it comes to the execution of SQL statements, accurate optimizer statistics are key. With the upcoming v18 release, PostgreSQL will preserve the optimizer statistics during an upgrade with dump/restore or pg_upgrade (see commit 1fd1bd8710 and following). With the beta testing season for PostgreSQL v18 opened, it is time to get acquainted with the new feature.
A word about statistics
First, let's clear up a frequent source of confusion. We use the word “statistics” for two quite different things in PostgreSQL:
- Information about the activities of the database: PostgreSQL gathers these monitoring data in shared memory and persists them across restarts in the
pg_statdirectory. You can access these data through thepg_stat_*views. - Information about the content and distribution of the data in the user tables:
ANALYZEgathers these data and stores them in the catalog tablespg_class,pg_statisticandpg_statistic_ext_data. These data allow the query planner to estimate the cost and result row count of query execution plans and allow PostgreSQL to find the best execution plan.
I'll talk about the latter kind of statistics here, and I call them “optimizer statistics” (as opposed to “monitoring statistics”).
Upgrade and optimizer statistics before PostgreSQL v18
Before PostgreSQL v18, there was no way to preserve optimizer statistics across a (major) upgrade. That was no big problem if you upgraded using pg_dumpall — loading the dump will automatically trigger autoanalyze. Waiting for the statistics collection to finish constitutes a additional delay until the database is ready for use. However, dump/restore is slow enough that that additional delay doesn't really matter much. At least you need no manual intervention to gather the statistics!
The situation with pg_upgrade was considerably worse. pg_upgrade dumps and restores only the metadata from the catalog tables and leaves the data files unchanged. pg_upgrade doesn
SELECT FOR UPDATE considered harmful in PostgreSQL
Posted by Laurenz Albe in Cybertec on 2025-06-17 at 06:00
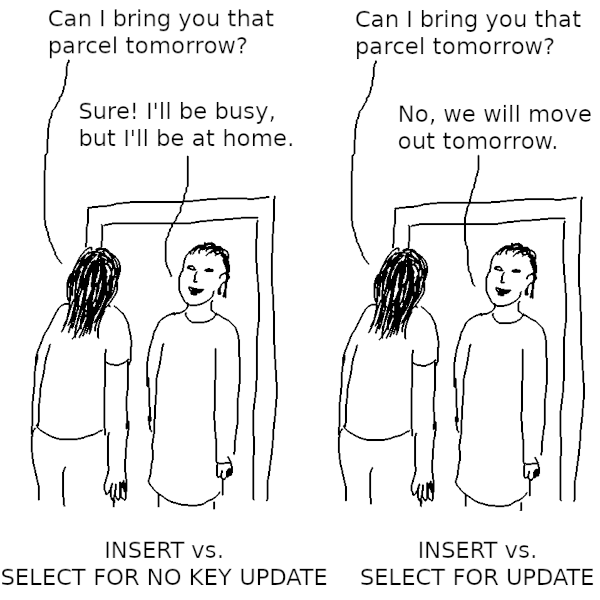
© Laurenz Albe 2025
Recently, while investigating a deadlock for a customer, I was again reminded how harmful SELECT FOR UPDATE can be for database concurrency. This is nothing new, but I find that many people don't know about the PostgreSQL row lock modes. So here I'll write up a detailed explanation to let you know when to avoid SELECT FOR UPDATE.
The motivation behind SELECT FOR UPDATE: avoiding lost updates
Data modifying statements like UPDATE or DELETE lock the rows they process to prevent concurrent data modifications. However, this is often too late. With the default isolation level READ COMMITTED, there is a race condition: a concurrent transaction can modify a row between the time you read it and the time you update it. In that case, you obliterate the effects of that concurrent data modification. This transaction anomaly is known as “lost update”.
If you don't want to use a higher transaction isolation level (and deal with potential serialization errors), you can avoid the race condition by locking the row as you read it:
START TRANSACTION; /* lock the row against concurrent modifications */ SELECT data FROM tab WHERE key = 42 FOR UPDATE; /* computation */ /* update the row with new data */ UPDATE tab SET data = 'new' WHERE key = 42; COMMIT;
But attention! The above code is wrong! To understand why, we have to dig a little deeper.
How PostgreSQL uses locks to maintain foreign key consistency
We need to understand how PostgreSQL guarantees referential integrity. Let's consider the following tables:
CREATE TABLE parent ( p_id bigint PRIMARY KEY, p_val integer NOT NULL ); INSERT INTO parent VALUES (1, 42); CREATE TABLE child ( c_id bigint PRIMARY KEY, p_id bigint REFERENCES parent );
Let's start a transaction and insert a new row in child that references the existing row in parent:
START TRANSACTION; INSERT INTO child VALUES (100, 1);
At this point, the new row is not yet visible to concurrent transactions, because we didn't yet commit the trans
[...]My PostgreSQL GSoC’25 Journey
Posted by ahmed gouda in Cybertec on 2025-06-17 at 00:00
- The Post will be Continuously Updated.
Postgres community bonding
The first phase of GSoC is Community Bonding where mentee gets to know the community of his Organization.
For Postgres i started searching for the communication channels used by contributors, i found out about Postgres mailing lists which unfortuanetly i hadn’t involved into that much till now, but also i discovered the PostgreSQL Hacking Discord channel and the Hacking Workshops they host every month to study and discuss PostgreSQL topics was a great thing for me.
Then i started searching about Currently on going PostgreSQL projects and unforuantely found out that there is not that much low hanging fruits in the main PostgreSQL engine itself but the Good part is that there was a lot of other Projects that integrate with Postgres and build on top of it which had a good amount of starter issues to help aspiring contributors get started one of them was pg_duckdb The official PostgreSQL extension for DuckDB where i opened a PR adding sqlsmith CI test
Coding Period
By The start of the coding period i started digging more into the pgwatch & pgwatch_rpc_server code and testing them with various workloads and options to enhance my understanding for their workflow and Good News! this give back Great results.
- discovered a segmentation violation issue that got immediately resolved and published under the pgwatch v3.4.0 release
- Also reading the code got me to have some enhancements ideas that i discussed with the maintainers and most of them were approved.
Now i needed to start working on my first milestone which was adding TLS encryption support to RPC channel, similar to all the things i have worked on here i sp
[...]Avoiding Timezone Traps: Correctly Extracting Date/Time Subfields in Django with PostgreSQL
Posted by Colin Copeland on 2025-06-16 at 19:00
Working with timezones can sometimes lead to confusing results, especially when combining Django's ORM, raw SQL for performance (like in PostgreSQL materialized views), and specific timezone requirements. I recently had an issue while aggregating traffic stop data by year, where all yearly calculations needed to reflect the 'America/New_York' (EST/EDT) timezone, even though our original data contained timestamp with time zone fields. We were using django-pgviews-redux to manage materialized views, and I mistakenly attempted to apply timezone logic to a date field that had no time or timezone information.
The core issue stemmed from a misunderstanding of how PostgreSQL handles EXTRACT operations on date types when combined with AT TIME ZONE, especially within a Django environment that defaults database connections to UTC.
PostgreSQL's Handling of Timestamps and Timezones
PostgreSQL's timestamp with time zone (often abbreviated as timestamptz) type is a common database type for storing date and time information. As per the PostgreSQL documentation:
For timestamp with time zone values, an input string that includes an explicit time zone will be converted to UTC (Universal Coordinated Time) using the appropriate offset for that time zone.
When you query a timestamptz column, PostgreSQL converts the stored UTC value back to the current session's TimeZone. You can see your session's timezone with SHOW TIME ZONE;. Django, by default, sets this session TimeZone to 'UTC' for all database connections. This is a sensible default for consistency but can be a source of confusion if you're also interacting with the database via psql or other clients that might use your system's local timezone (e.g., 'America/New_York' on my Mac via Postgres.app).
You can change the session timezone and observe its effect:
tztest=# SHOW TIME ZONE;
-- TimeZone
-- ------------------
-- America/New_York (If running from my MacNisha Moond
Posted by Andreas 'ads' Scherbaum on 2025-06-16 at 14:00
PgPedia Week, 2025-06-15
Posted by Ian Barwick on 2025-06-16 at 10:25
Top posters
Number of posts in the past two months
 Ian Barwick - 9
Ian Barwick - 9- David Wheeler (Tembo) - 6
- Andreas 'ads' Scherbaum - 6
- Andreas Scherbaum - 5
- Umair Shahid (Stormatics) - 5
- semab tariq (Stormatics) - 5
- Andrew Atkinson - 4
- Tomas Vondra - 4
- Karen Jex (Crunchy Data) - 3
- Radim Marek - 3
Top teams
Number of posts in the past two months
- Stormatics - 11
- Cybertec - 9
- Xata - 9
- EDB - 7
- postgres-contrib.org - 6
- Tembo - 6
- Crunchy Data - 4
- Percona - 4
- Hornetlabs Technology - 3
- PostGIS - 2
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.